Let's talk!
We'de love to hear what you are working on. Drop us a note here and we'll get back to you within 24 hours.
We'de love to hear what you are working on. Drop us a note here and we'll get back to you within 24 hours.
Yelp is a localized search engine for companies in your area. People talk about their experiences with that company in the form of reviews, which is a great source of information. Customer input can assist in identifying and prioritizing advantages and problems for future business development.
We now have access to a variety of sources thanks to the internet, where people are prepared to share their experiences with various companies and services. We may exploit this opportunity to gather some useful data and generate some actionable intelligence to provide the best possible client experience.
We can collect a substantial portion of primary and secondary data sources, analyze them, and suggest areas for improvement by scraping all of those evaluations. Python has packages that make these activities very simple. We can choose the requests library for web scraping since it performs the job and is very easy to use
By analyzing the website via a web browser, we may quickly understand the structure of the website. Here is the list of possible data variables to collect after researching the layout of the Yelp website:
The requests module makes it simple to get files from the internet. The requests module can be installed by following these steps:
pip install requests
To begin, we go to the Yelp website and type in “restaurants near me” in the Chicago, IL area.
We’ll then import all of the necessary libraries and build a panda DataFrame.
import pandas as pd import time as t from lxml import html import requestsreviews_df=pd.DataFrame()
Downloading the HTML page using request.get()
import requests
searchlink= 'https://www.yelp.com/search?find_desc=Restaurants&find_loc=Chicago,+IL'
user_agent = ‘ Enter you user agent here ’
headers = {‘User-Agent’: user_agent}
Get the user agent here
To scrape restaurant reviews for any other location on the same review platform, simply copy and paste the URL. All you have to do is provide a link.
page = requests.get(searchlink, headers = headers) parser = html.fromstring(page.content)
The Requests.get() will be downloaded in the HTML page. Now we must search the page for the links to various eateries.
businesslink=parser.xpath('//a[@class="biz-name js-analytics-click"]')
links = [l.get('href') for l in businesslink]
Because these links are incomplete, we will need to add the domain name.
u=[]
for link in links:
u.append('https://www.yelp.com'+ str(link))
We now have most of the restaurant titles from the very first page; each page has 30 search results. Let’s go over each page one by one and seek their feedback.
for item in u: page = requests.get(item, headers = headers) parser = html.fromstring(page.content)
A div with the class name “review review — with-sidebar” contains the reviews. Let’s go ahead and grab all of these divs.
xpath_reviews = ‘//div[@class=”review review — with-sidebar”]’ reviews = parser.xpath(xpath_reviews)
We would like to scrape the author name, review body, date, restaurant name, and star rating for each review.
for review in reviews:
temp = review.xpath('.//div[contains(@class, "i-stars i- stars--regular")]')
rating = [td.get('title') for td in temp] xpath_author = './/a[@id="dropdown_user-name"]//text()'
xpath_body = './/p[@lang="en"]//text()'
author = review.xpath(xpath_author)
date = review.xpath('.//span[@class="rating-qualifier"]//text()')
body = review.xpath(xpath_body)
heading= parser.xpath('//h1[contains(@class,"biz-page-title embossed-text-white")]')
bzheading = [td.text for td in heading]
For all of these objects, we’ll create a dictionary, which we’ll then store in a pandas data frame.
review_dict = {‘restaurant’ : bzheading,
‘rating’: rating,
‘author’: author,
‘date’: date,
‘Review’: body,
}
reviews_df = reviews_df.append(review_dict, ignore_index=True)
We can now access all of the reviews from a single website. By determining the maximum reference number, you can loop across the pages. A <a> tag with the class name “available-number pagination-links anchor” contains the latest page number.
page_nums = '//a[@class="available-number pagination-links_anchor"]' pg = parser.xpath(page_nums)max_pg=len(pg)+1
Here we will scrape a total of 23,869 reviews with the aforementioned script, for about 450 eateries and 20-60 reviews for each restaurant.
Let’s launch a jupyter notebook and do some text mining and sentiment analysis.
First, get the libraries you’ll need.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
We will save the data in a file named all.csv.
data=pd.read_csv(‘all.csv’)
Let’s take a look at the data frame’s head and tail.
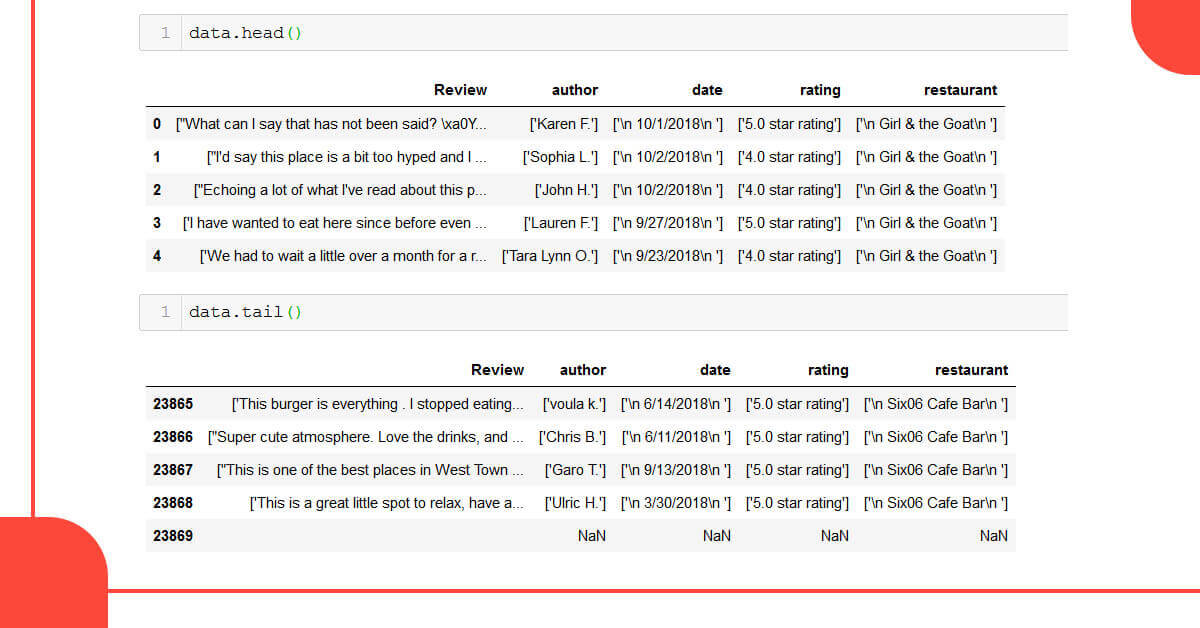
With 5 columns, we get 23,869 records. As can be seen, the data requires formatting. Symbols, tags, and spaces that aren’t needed should be eliminated. There are a few Null/NaN values as well.
Remove all values that are Null/NaN from the data frame.
data.dropna()
We’ll now eliminate the extraneous symbols and spaces using string slicing.
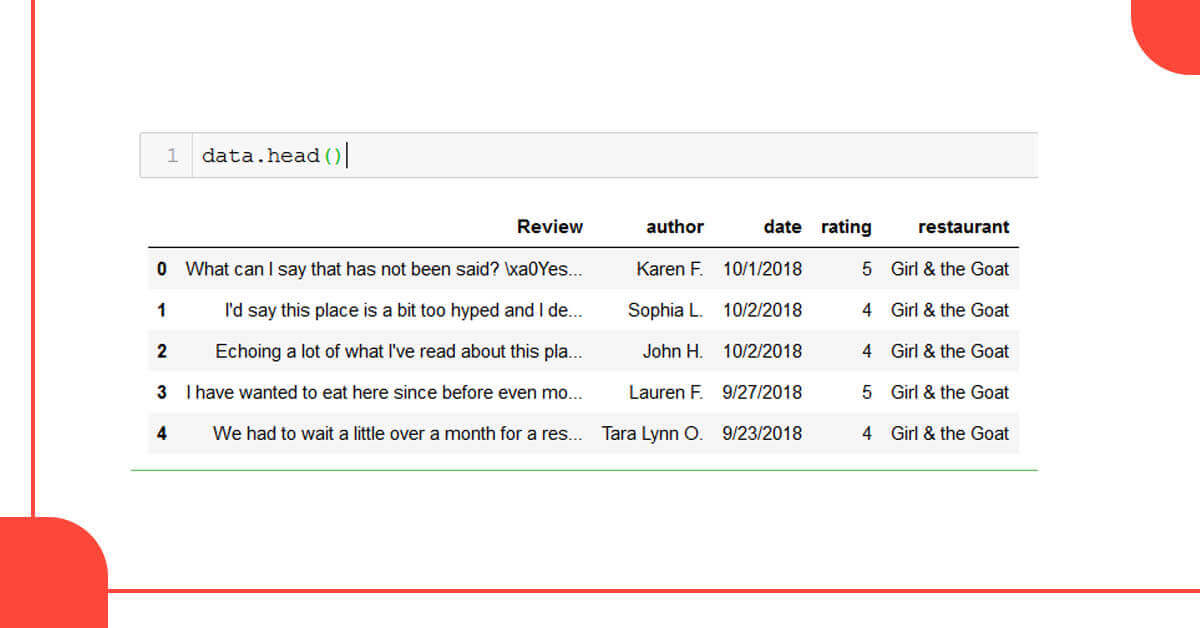
data['Review']=data.Review.str[2:-2] data['author']=data.author.str[2:-2] data['date']=data.date.str[12:-8] data['rating']=data.rating.str[2:-2] data['restaurant']=data.restaurant.str[16:-12] data['rating']=data.rating.str[:1]
Discovering the further data
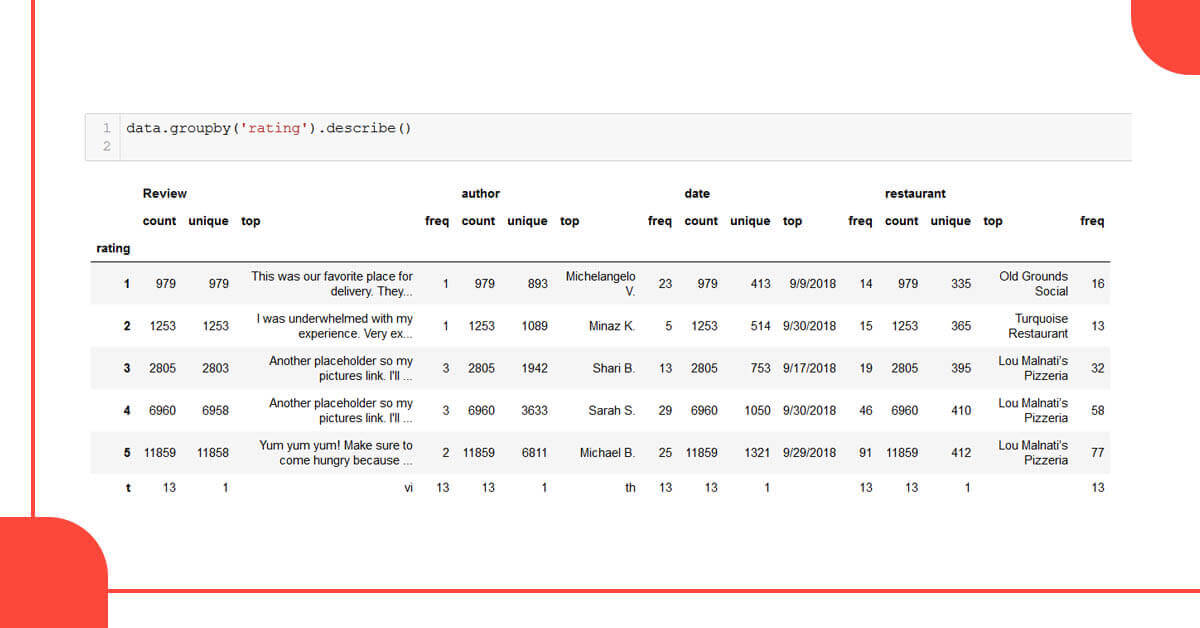
The highest number of reviews with a 5-star luxury rating is 11,859, while the lowest number of reviews with a 1 star rating is 979. However, few records have a ‘t’ grade that is uncertain. These records ought to be discarded.
data.drop(data[data.rating=='t'].index , inplace =True)
We can develop a new function called review _length to help us better comprehend the data. The number of characters in each review will be stored in this column, and any white spaces in the review will be removed.
data['review_length'] = data['Review'].apply(lambda x: len(x) - x.count(' '))Let’s make some graphs and analyze the data now.
hist = sns.FacetGrid(data=data, col='rating') hist.map(plt.hist, 'review_length', bins=50)
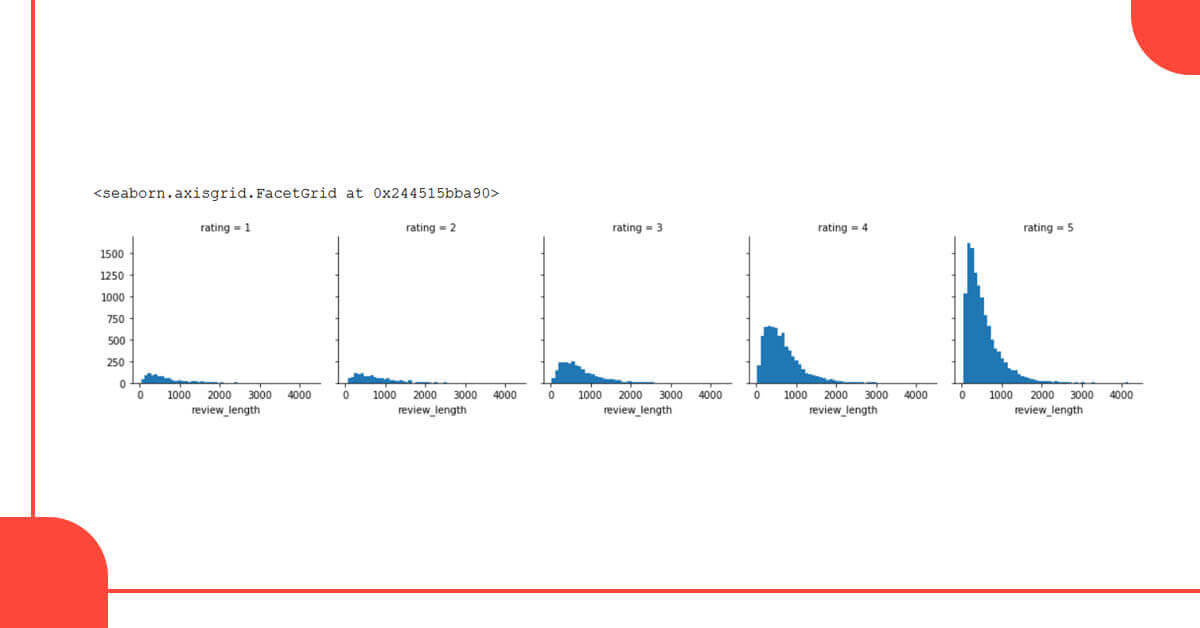
We can see that the number of 4- and 5-star reviews is increasing. For all ratings, the distribution of review durations is relatively similar. Let's do the same thing using a box plot.
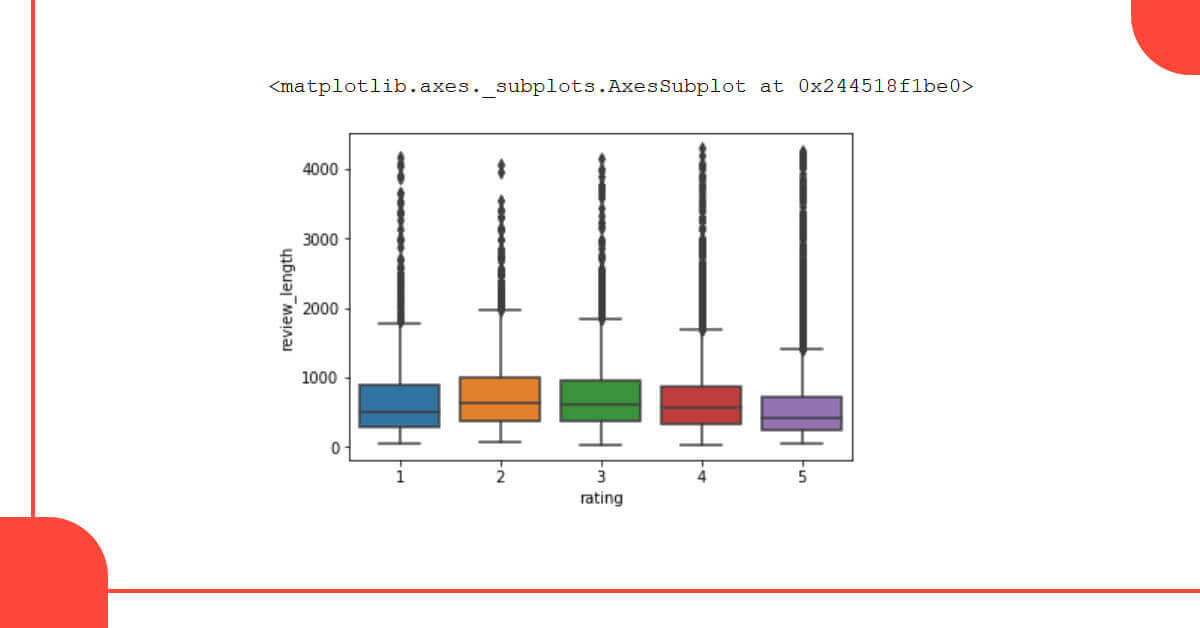
sns.boxplot(x='rating', y='review_length', data=data)
According to the box plot, reviews with 2- and 3-star ratings have longer reviewed than reviews with a 5-star rating. However, the number of dots above the boxes indicates that there are several outliers for each star rating. As a result, the duration of a review isn’t going to be very beneficial for our sentiment analysis.
Only the 1 star and 5-star ratings will be used to evaluate whether a review is good or negative. Let’s make a new data frame to keep track of the one- and five-star ratings.
df = data[(data['rating'] == 1) | (data['rating'] == 5)] df.shapeOutput:(12838, 6)
We now have 12,838 records for 1- and 5-star ratings out of 23,869 total records.
The review text must be properly formatted in order to be used for analysis. Let’s take a look at a sample to see what we’re up against.
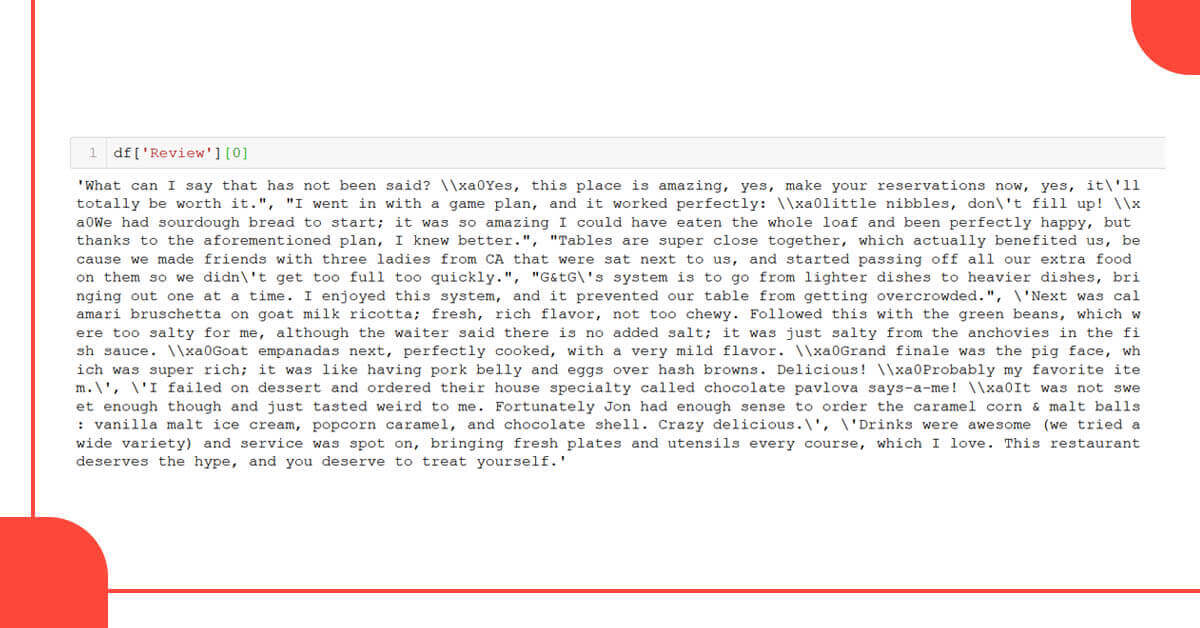
There appear to be numerous punctuation symbols as well as some unknown codes such as ‘\xa0’. In Latin1 (ISO 8859–1), ‘\xao’ is a non-breaking space (see chr) (160). You should substitute a space for it. Let’s now write a function that removes all punctuation, stops words, and then lemmatizes the text.
Bag of words is a common method for text pre-processing in natural language processing. A list of words, regardless of their grammar or arrangement, is represented by a bag-of-words. The bag-of-words model is widely employed, in which the frequency of each word is utilized to train a classifier.
Lemmatization is the process of combining together variant versions of words so that they can be studied as a single phrase, or lemma. A dictionary form of a word will always be returned by lemmatization. For example, the words typing, typed, and programming will all be regarded as a single word, “type.” This feature will be extremely beneficial to our research.
import string # Imports the library
import nltk # Imports the natural language toolkit
nltk.download('stopwords') # Download the stopwords dataset
nltk.download('wordnet')
wn=nltk.WordNetLemmatizer()from nltk.corpus import stopwords
stopwords.words('english')[0:10]Output: ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're"]
These punctuations are frequently used and are of a neutral nature. They have no positive or negative meaning and can be ignored.
def text_process_lemmatize(revw):
"""
Takes in a string of text, then performs the following:
1. Remove all punctuation
2. Remove all stopwords
3. create a list of the cleaned text
4. Return Lemmatize version of the list
"""
# Replace the xa0 with a space
revw=revw.replace('xa0',' ')
# Check characters to see if they are in punctuation
nopunc = [char for char in revw if char not in string.punctuation] # Join the characters again to form the string.
nopunc = ''.join(nopunc)
# Now just remove any stopwords
token_text= [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]
# perform lemmatization of the above list
cleantext= ' '.join(wn.lemmatize(word) for word in token_text)
return cleantext
Let’s use the function we just constructed to handle our review column.
df['LemmText']=df['Review'].apply(text_process_lemmatize)
The collection of lemmas in df [‘LemmText’] must be converted to vectors so that a machine learning model and Python could use and interpret it. Vectorizing is the term for this procedure. This procedure will generate a matrix with each review as a row and each unique lemma as a column, with the number of occurrences of each lemma in each column. The scikit-learn library’s Count Vectorizer and N-grams procedure will be used. We’ll simply look at unigrams in this section.
from sklearn.feature_extraction.text import CountVectorizer ngram_vect = CountVectorizer(ngram_range=(1,1)) X_counts = ngram_vect.fit_transform(df['LemmText'])
Let’s use scikit-train test split learns to create training and testing data sets.
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3)#0.3 mean the training set will be 70% and test set will be 30%
For sentiment prediction, we’ll utilise Multinomial Naive Bayes. Negative reviews receive a one-star rating, while favourable reviews receive a five-star rating. Let’s build a MultinomialNB model that fits the X train and y train data.
from sklearn.naive_bayes import MultinomialNB nb = MultinomialNB() nb.fit(X_train,y_train)
Now let’s make a prediction on the test X test set.
NBpredictions = nb.predict(X_test)
Let’s compare our model’s predictions to the actual star ratings obtained from y test.
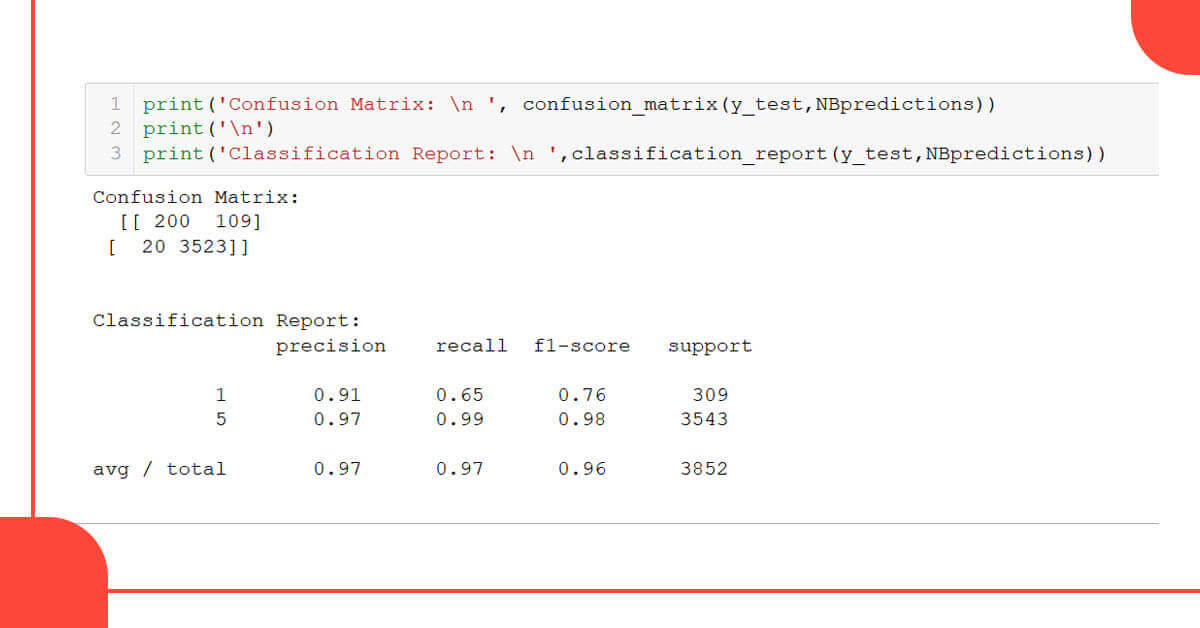
from sklearn.metrics import confusion_matrix,classification_report
print(confusion_matrix(y_test,NBpredictions))
print('\n')
print(classification_report(y_test,NBpredictions))
The model has a 97% accuracy, which is excellent. Based on the customer’s review, this algorithm can predict whether he liked or disliked the restaurant.
Looking to scrape Yelp data and other restaurant reviews? Contact Foodspark today or ask for a free quote!
This blog will explain the working of the algorithm using web scraping services and what kind of steps will be required to build a structured algorithm.
The following steps are frequently required when creating a sophisticated algorithm:
After these processes are finished, you can gradually add more features, like Machine Learning, exploratory data analysis or insight extraction, and visualization.
This is the code used to extract data from Yelp page and give you an idea of what algorithm is used.
import requests
from bs4 import BeautifulSoup
import timecomment_list = list()
for pag in range(1, 29):
time.sleep(5)
URL = "https://www.yelp.com/biz/the-cortez-raleigh?osq=Restaurants&start="+str(pag*10)+"&sort_by=rating_asc"
print('downloading page ', pag*10)
page = requests.get(URL)
#next step: parsing
soup = BeautifulSoup(page.content, 'lxml')
soupfor comm in soup.find("yelp-react-root").find_all("p", {"class" : "comment__373c0__Nsutg css-n6i4z7"}):
comment_list.append(comm.find("span").decode_contents())
print(comm.find("span").decode_contents())
As you can see, it’s quite little and simple to comprehend if you’ve worked with Python and some of its modules before.
Developing a control panel will be an efficient method to structure the code.
Simultaneously, the algorithm must be written in sections that correspond to the best programming procedures:
The first stage, like with any acceptable algorithm, will be to dedicate a small part of code to the libraries we’ll be using across our entire code. You won’t need to use pip to install anything because all of the libraries You will need are already included in the Python bundle.
import requests from bs4 import BeautifulSoup import time from textblob import TextBlob import pandas as pd
You can manage the webpages that are downloaded using BeautifulSoup by utilizing this collection of settings. You will just need to use two to present a simple example. You will need a lot of data to effectively direct scraper. To build the connection, you will need to link each restaurant, the number of review pages that you would like to scrape, and the name of the restaurant to include in the dataset.
Either a stacked list or a dictionary would be the best approach to keep this information (which is the equivalent of a JavaScript Object, NoSQL if you wish). Once you’ve become used to using dictionaries, they can help you simplify a lot of your work and make your code more understandable.
rest_dict = [
{ "name" : "the-cortez-raleigh",
"link" : "https://www.yelp.com/biz/the-cortez-raleigh?osq=Restaurants&start=",
"pages" : 3
},
{ "name" : "rosewater-kitchen-and-bar-raleigh",
"link" : "https://www.yelp.com/biz/rosewater-kitchen-and-bar-raleigh?osq=Restaurants&start=",
"pages" : 3
}
]
You will want to describe every single detail of the function, if you just want the code, It is recommended to download it directly; compiling and pasting these distinct lines of code into your IDE would be a pain when you can do it with a single click.
Now that you have all of the necessary information, you can create algorithm, which you will call cape scraper. The rationale is straightforward, as the code will follow a set of steps:
def scraper(rest_list): all_comment_list = list() for rest in rest_list: comment_list = list()
It will cycle through all of the dictionaries in the list first.
for pag in range(1, rest['pages']):
Also add a try statement so that you don’t have to start over if there’s an error in the code or a problem with our connection that causes the algorithm to stop working. We need to take safeguards to avoid our algorithm from halting because faults are typical during web scraping because they are so dependent on the structure of a website that we have not constructed ourselves. If this happens, you will either have to spend more time figuring out where the algorithm has stopped and tuning the scraping parameters, given that you have been able to save the data thus far, or you will have to start over.
try:
To avoid IP being refused, we will impose a 5-second delay before initiating a request. When you perform too many queries, the website often recognizes that we aren’t human and decides to deny our connection request. The algorithm will throw an error unless we have a try statement.
time.sleep(5)
Connect to Yelp scraper and copy the HTML, then repeat for the appropriate amount of pages.
osq=Restaurants&start="+str(pag*10)+"&sort_by=rating_asc" URL = rest['link']+str(pag*10) print(rest['name'], 'downloading page ', pag*10) page = requests.get(URL)
Convert the HTML into a code that beautifulsoup can understand. This process must work because it’s the only way we’ll be able to extract data using the library’s functions.
#next step: parsing soup = BeautifulSoup(page.content, 'lxml') soup
Take the reviews out of this 1,000-line string. After a thorough examination of the code, we were able to determine where the reviews were stored in HTML elements. This code will retrieve the content of these components to the letter.
for comm in soup.find("yelp-react-root").find_all("p", {"class" : "comment__373c0__Nsutg css-n6i4z7"}):
We will save the content of a single restaurant in a list named comment list that contains each review matched with the restaurant’s name.
comment_list.append(comm.find("span").decode_contents())
print(comm.find("span").decode_contents())
except:
print("could not work properly!")
We will save the reviews in comment list into a general list named all comment list before scraping the next page. The comment list variable will be reset in the following iteration.
all_comment_list.append([comment_list, rest['name']]) return all_comment_list
Finally, you will be able to execute the algorithm with only one line of code and save all of the results in a list named reviews.
reviews = scraper(rest_dict)
Looking to scale the Yelp Downloading algorithm using Yelp data scraper? Contact FoodSpark, today!!
This is the third in a series of articles that uses BeautifulSoup to scrape Yelp restaurant reviews and then apply Machine Learning to extract insights from the data. In this article, you will use the code to extract all the reviews in a list. The script will be as follows:
import requests
from bs4 import BeautifulSoup
import time
from textblob import TextBlob
import pandas as pd#we use these argument to scrape the website
rest_dict = [
{ "name" : "the-cortez-raleigh",
"link" : "https://www.yelp.com/biz/the-cortez-raleigh?osq=Restaurants&start=",
"pages" : 3
},
{ "name" : "rosewater-kitchen-and-bar-raleigh",
"link" : "https://www.yelp.com/biz/rosewater-kitchen-and-bar-raleigh?osq=Restaurants&start=",
"pages" : 3
}
]#scraping function
def scrape(rest_list):
all_comment_list = list()
for rest in rest_list:
comment_list = list()
for pag in range(1, rest['pages']):
try:
time.sleep(5)#URL = "https://www.yelp.com/biz/the-cortez-raleigh?osq=Restaurants&start="+str(pag*10)+"&sort_by=rating_asc"
URL = rest['link']+str(pag*10)
print(rest['name'], 'downloading page ', pag*10)
page = requests.get(URL)#next step: parsing
soup = BeautifulSoup(page.content, 'lxml')
soupfor comm in soup.find("yelp-react-root").find_all("p", {"class" : "comment__373c0__Nsutg css-n6i4z7"}):
comment_list.append(comm.find("span").decode_contents())
print(comm.find("span").decode_contents())
except:
print("could not work properly!")
all_comment_list.append([comment_list, rest['name']])
return all_comment_list#store all reviews in a list
reviews = scrape(rest_dict)
Here in the script, the output of the function will be saved in a variable known as reviews. While printing the variable, the result will be:

The nested list’s structure follows this pattern:
[[[review1, review2], restaurant1], [[review1, review2], restaurant2]]
It will now be converted into DataFrame using Pandas
You will need to develop a DataFrame to hold all of the information now that you have established a list using the ratings and their respective restaurants.
df = pd.DataFrame(reviews)
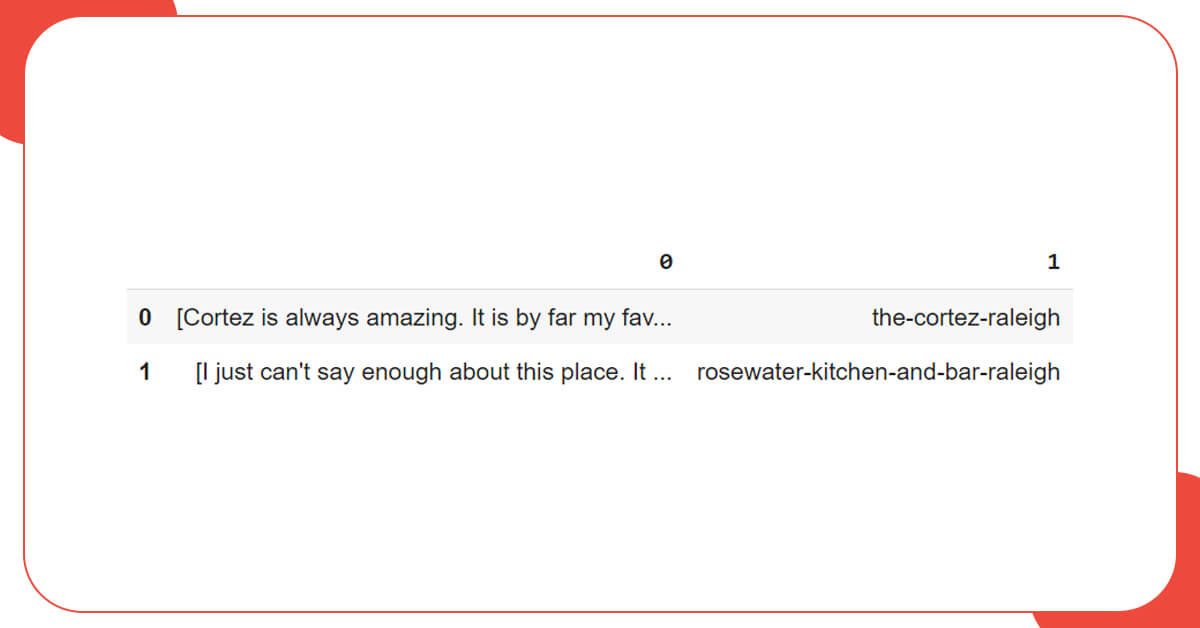
Here, we will try to persuade this hierarchical list into a DataFrame directly, and will end up with a column full of listings and another column with a single restaurant title. To correctly update the data, we will use the explode function, which creates a single row for each element of the list where it’s used, in this example, column 0.
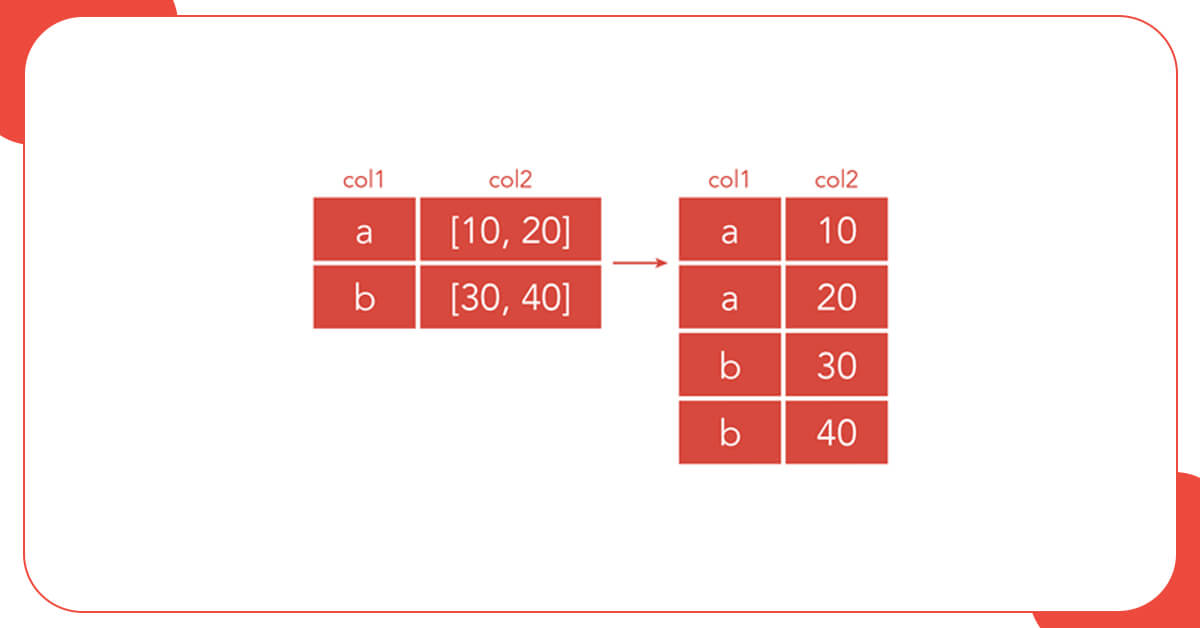
df = df.explode(0)
The dataset is now appropriately structured, as you can see in the image. Each review has a restaurant associated with it.
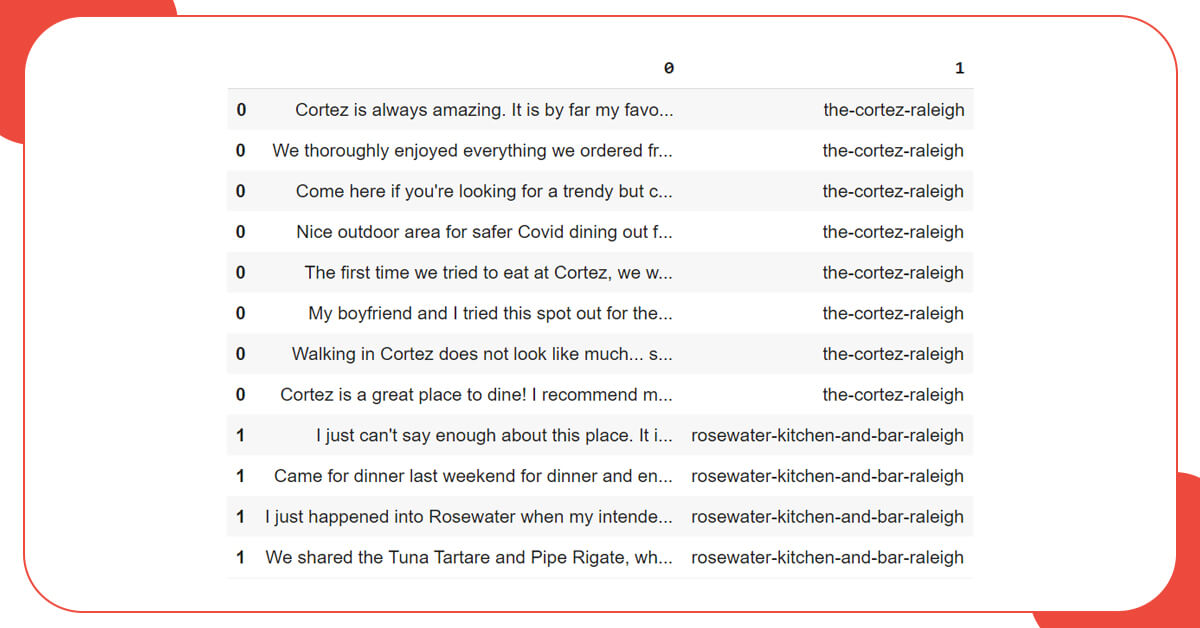
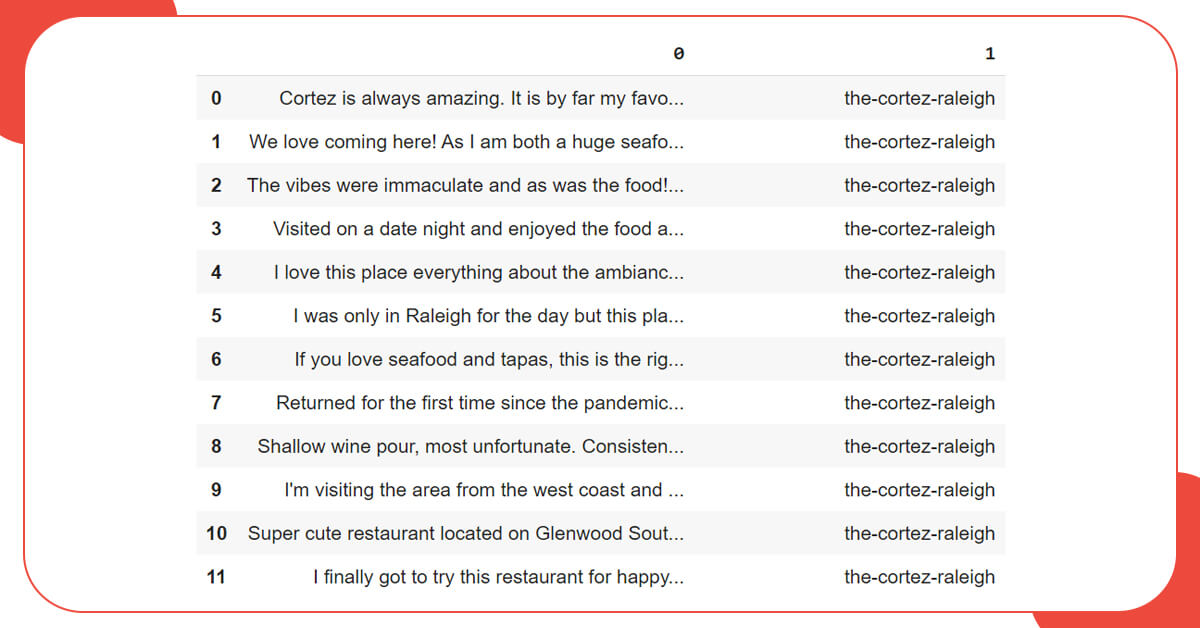
Because the current samples are only numbered with 0 and 1, the only thing left to do is reset the index.
df = df.reset_index(drop=True) df[0:10]
It is complicated to extract restaurant ratings that were previously assigned to each review available on the website. You will need sentiment analysis that will try to discover a solution to the missing information. The NLP model’s interferences regarding values will take the place of each review’s star rating. Obviously, working with the information is an experiment, and sentiment analysis is independent on the model that we employ which is not always precise.
We will use TextBlob, a simple library that already includes a pre-trained algorithm for the task. Because you will have to apply it to every review, we will first develop a function that returns the estimated sentiment of a paragraph in a range of -1 to 1.
def perform_sentiment(x): testimonial = TextBlob(x) #testimonial.sentiment (polarity, subjectvity) testimonial.sentiment.polarity #sentiment_list.append([sentence, testimonial.sentiment.polarity, testimonial.subjectivity]) return testimonial.sentiment.polarity
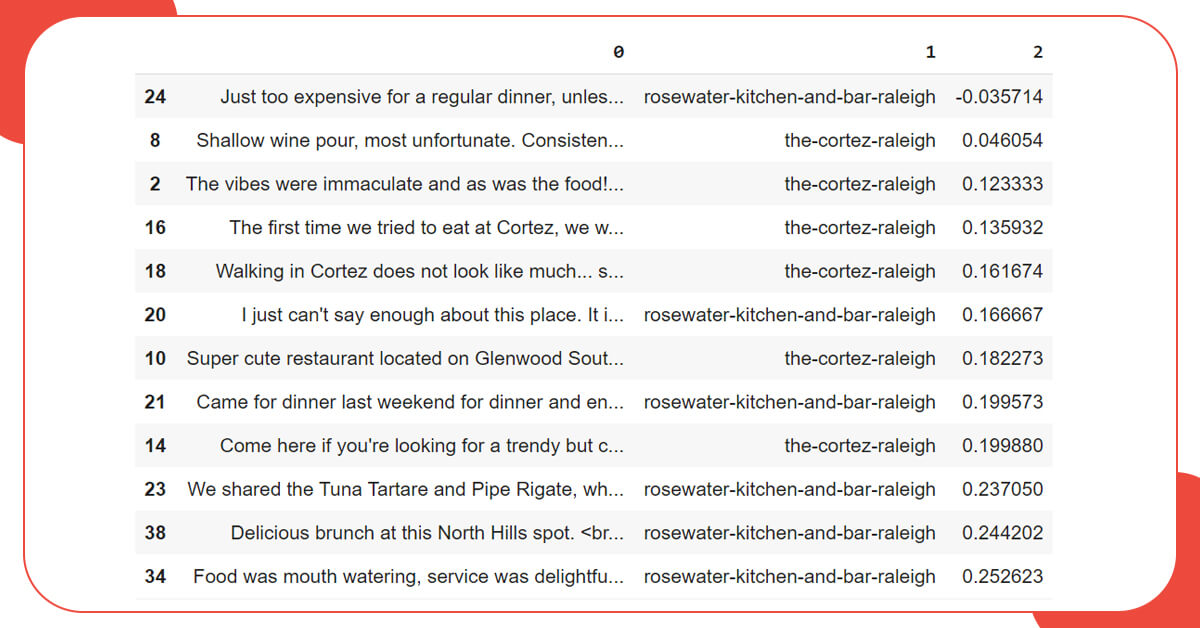
After developing the function, we will use pandas and apply method to add a new column of our dataset that will hold algorithm analysis results. The sort values method will then be used to sort all of the reviews, starting with the negative ones.
The final dataset will be:
To continue with the experiment, we will now extract one of most frequently used words in a dataset division. However, there is a problem. Although certain words have the same root, such as “eating” and “ate,” the algorithm will not automatically place them in the same category because they are different when converted to binary. As a solution to this difficulty, we will employ lemmatization, an NLP pre-processing approach.
Lemmatization may isolate the core of any existing word, removing any potential variation and enabling the data to be normalized. Lemmatizers are basic models that must be pre-trained before they can be built. To import a lemmatizer, we will use the spacy library.
!pip install spacy
Spacy is an open-source NLP library that includes a lemmatizer and many pre-trained models. This program will lemmatize all or most of the words in a single message and provide the frequency of each term (the number of times they have been used). We will arrange the results in ascending order to indicate which words have appeared the most frequently in a set of evaluations.
def top_frequent(text, num_words):
#frequency of most common words
import spacy
from collections import Counternlp = spacy.load("en")
text = text
#lemmatization
doc = nlp(text)
token_list = list()
for token in doc:
#print(token, token.lemma_)
token_list.append(token.lemma_)
token_list
lemmatized = ''
for _ in token_list:
lemmatized = lemmatized + ' ' + _
lemmatized#remove stopwords and punctuations
doc = nlp(lemmatized)
words = [token.text for token in doc if token.is_stop != True and token.is_punct != True]
word_freq = Counter(words)
common_words = word_freq.most_common(num_words)
return common_words
We will extract the most common words from the worst-rated reviews, rather than the complete list of reviews. The information has already been sorted to place the worst ratings at the front, so all that remains is to build a unique string that contains all of the reviews. To convert the review list into a string, we will use the join function.
text = ' '.join(list(df[0].values[0:20]))
texttop_frequent(text, 100)[('great', 22),
('<', 21),
('come', 16),
('order', 16),
('place', 14),
('little', 10),
('try', 10),
('nice', 10),
('food', 10),
('restaurant', 10),
('menu', 10),
('day', 10),
('butter', 9),
('drink', 9),
('dinner', 8),
...
If you are looking to perform an EDA on Yelp data then, you can contact Foodspark today!!
January 21, 2025 B2B marketplaces use data collection to expand and maintain relevance in the food industry. Organizations can improve...
Read moreJanuary 2, 2025 Web scraping has now become an important strategy in the accelerating world of e-commerce, especially for businesses...
Read more