Let's talk!
We'de love to hear what you are working on. Drop us a note here and we'll get back to you within 24 hours.
We'de love to hear what you are working on. Drop us a note here and we'll get back to you within 24 hours.

Ordering online has become an extremely important part of the everyday lives. So, what should we all do if we open an online food delivery app as well as try to decide what to eat tonight?
Yes, you are right! We will look at ratings first and then bestsellers or top dishes, might be some latest reviews and done! We will place an order! It is a general process for the Scrape Online Food Delivery App like ZOMATO. We use Zomato when we wish to discover any restaurants or when we want to order online. Zomato reviews and ratings play an important role in drawing customers.
Both restaurant dining and online delivery are heavily predisposed by reviews and ratings of the customers. However, consumer’s perception about ambience, service, and food is also very important as it helps the restaurateurs recognize potential problems and work on that consequently.
In this blog, we will take you all the way through the procedure followed before you apply any modelling method. To feed the good data to an algorithm is extremely important to produce accurate results.
We have a dataset with details of around 12000 restaurants of Bengaluru (till Mar, 2019) and we will be utilizing some preprocessing methods to prepare data for more analysis.
Efficiently, we will show you how we scrape Zomato reviews of every restaurant to make further analysis.
#Loading the necessary packages
import numpy as np # For Numerical Python
import pandas as pd # For Panel Data Analysis
import re # library for handling regular expressions (string formatting)
# To Disable Warnings
import warnings
warnings.filterwarnings("ignore")
After importing the necessary libraries, you need to read data in the Python environment through pd.read_csv()
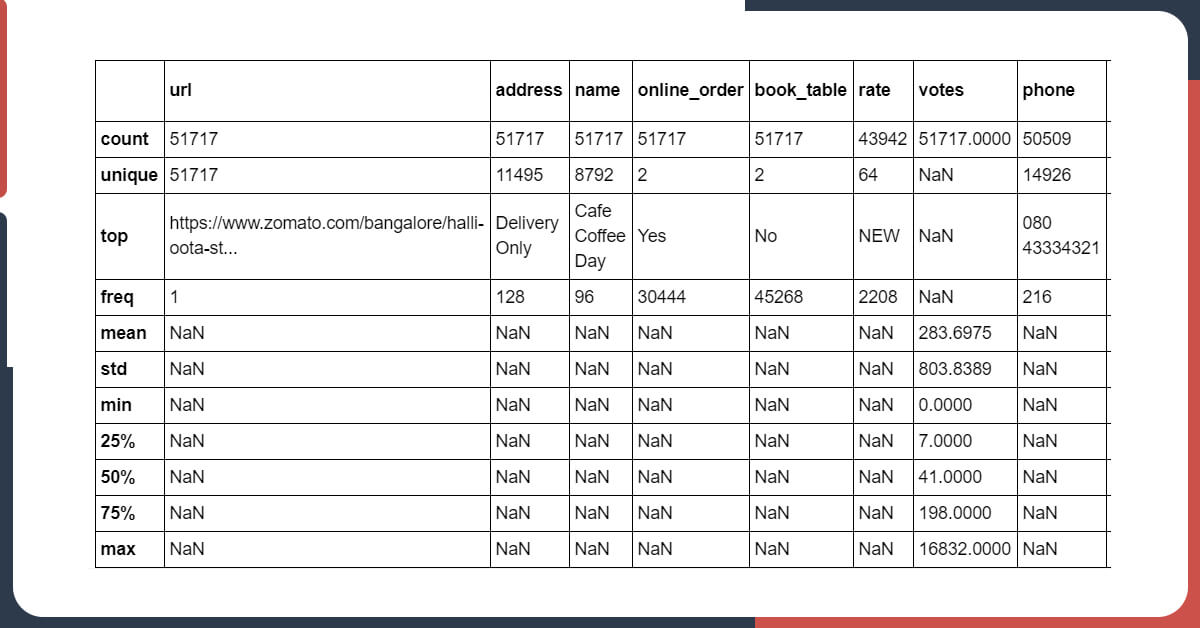
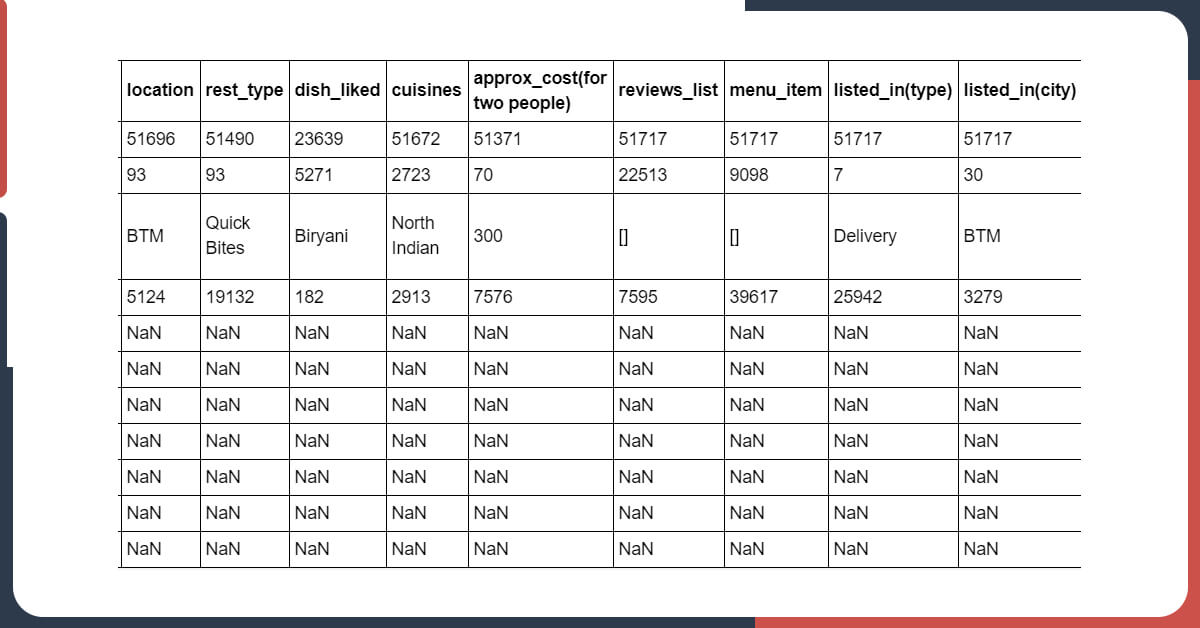
data.info() <class 'pandas.core.frame.dataframe'=""> RangeIndex: 51717 entries, 0 to 51716 Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 url 51717 non-null object 1 address 51717 non-null object 2 name 51717 non-null object 3 online_order 51717 non-null object 4 book_table 51717 non-null object 5 rate 43942 non-null object 6 votes 51717 non-null int64 7 phone 50509 non-null object 8 location 51696 non-null object 9 rest_type 51490 non-null object 10 dish_liked 23639 non-null object 11 cuisines 51672 non-null object 12 approx_cost(for two people) 51371 non-null object 13 reviews_list 51717 non-null object 14 menu_item 51717 non-null object 15 listed_in(type) 51717 non-null object 16 listed_in(city) 51717 non-null object dtypes: int64(1), object(16) memory usage: 6.7+ MB
You will get There 51717 rows as well as 17 columns in this dataset excluding votes, all the other columns are objective type.
After that, we will do a .describe() for getting more information.
data.describe(include = 'all')
Our attention in this analysis comes in a reviews_list column therefore, we will overlook cleaning as well as analyzing all other variables.
Note: For more study, please use different matplotlib and seaborn plots to get more insights of the overall data. Like, checking for unique restaurants, the most ideal cuisines, ratings amongst various outlets of similar restaurants, etc.

`data.rename(columns= {'listed_in(type)': 'Type', 'listed_in(city)': 'City', 'reviews_list' : 'Reviews'}, inplace = True)Let’s take a look at these Reviews columns
data.Reviews.value_counts
It shows that reviews of all outlets have been captured in the list format together with individual ratings for all particular reviews.
Also, some outlets don’t provide any reviews. In case you need, you can proceed and drop these rows.
data = data[data.Reviews != '[]'] data.shape #check the shape of the data after dropping the rows (44122, 17)
Therefore, now there are more than 44122 rows with 17 columns.
More details about Reviews columns.
Let’s observe reviews for a single restaurant as well as try to recognize how data was gathered.
data.Reviews[0] #checking the first row of the Reviews column
It shows that for every restaurant, these reviews are recorded as a tuple of reviews and ratings as well as clubbed together within the list as well as passed like a string.
We needed individual reviews as well as ratings for one restaurant for more text analysis so we are just showing it to you here:
data_new = data[[‘name’,’Reviews’]] #keeping name and reviews columns
#rename the name column to Name
data_new.rename(columns= {'name': 'Name'}, inplace = True)
#resetting the index
data_new.reset_index(inplace = True)

We will make a function that will provide ant index values between 0 as well as the length of data frames above as well as print out the data frame of Reviews and Ratings together with a restaurant’s name. Here is the function given that does that:
def rating_reviews(value):
df = data_new.iloc[value]
name = df.Name
Reviews = df.Reviews.replace("RATED\\n", "")
Reviews = Reviews.replace("\'", "")
Reviews = Reviews.strip('[]') #convert from string of list to str
Reviews = Reviews.split("), (R") #spilt at "), (R" so as to differentiate between individual tuples
Reviews_df = pd.DataFrame({'Text':Reviews})
#Constructing 2 columns to store Rating and Reviews separately
Reviews_df['Rating'] = Reviews_df.Text.apply(lambda x: x.split(', ')[0])
Reviews_df['Review'] = Reviews_df.Text.apply(lambda x: x.split(', ')[1])
#define another function to clean Rating and Review columns
def clean_text(x):
text = x.replace("ated", "")
text = text.replace("R", "")
text = re.sub(r"[-()\"#/@;:<>{}`+=~|.!?,']", "", text)
text = text.lower()
return text
Reviews_df['Rating'] = Reviews_df['Rating'].apply(clean_text)
Reviews_df.Rating = Reviews_df.Rating.astype(float)
Reviews_df.Rating = round(Reviews_df.Rating/10,1)
#additional cleaning so as to make it better prepared for text analysis
def clean_text2(text):
text = text.lower().strip() #converting to lower form
text = re.sub(r"i'm", "i am", text)
text = re.sub(r"he's", "he is", text)
text = re.sub(r"she's", "she is", text)
text = re.sub(r"that's", "that is", text)
text = re.sub(r"what's", "what is", text)
text = re.sub(r"where's", "where is", text)
text = re.sub(r"how's", "how is", text)
text = re.sub(r"\'s", " is", text)
text = re.sub(r"\'ll", " will", text)
text = re.sub(r"\'ve", " have", text)
text = re.sub(r"\'re", " are", text)
text = re.sub(r"\'d", " would", text)
text = re.sub(r"won't", "will not", text)
text = re.sub(r"can't", "cannot", text)
text = re.sub(r"n't", " not", text)
text = re.sub(r">br<", " ", text)
text = re.sub(r"([-?.!,/\"])", r" \1 ", text)
#removing all kinds of punctuations
text = re.sub(r"[-()\"#/@;:<>{}`+=~|.!?,'*\\]", "", text)
text = re.sub(r"[ ]+", " ", text)
text = text.rstrip().strip()
return text
Reviews_df.Review = Reviews_df.Review.apply(clean_text2)
Reviews_df = Reviews_df[['Rating', 'Review']]
print("Name of the restaurant is :", name)
return Reviews_df
rating_reviews(1688) #a sample
All the reviews for every index (or restaurant) is taken as well as then cleaned for bringing an organized format. We have used library “re” to do this.
The functions may look daunting due to its size however, once you do that step-by-step, you would understand how easier it is.
Suggestion: You can take any restaurant and apply every line of the given functions separately and you will know that this is quite logical and very easy.
Creating Another Customized Function
A function that would take a restaurant’s name and provide the directories of all the branches together with total reviews for all of them. A given variant of “rating_reviews” job will be needed here with only a smaller variation in a return statement for capturing the review length. The new function’s name is called index_length().
Now, whatever you need to investigate more, just take the index as well as pass that into given “rating_reviews” job and you would see the real reviews as well as ratings to go on as well as do the necessary analysis.
#same function with a slight variation in the return statement
def rating_reviews_2(value):
df = data_new.iloc[value]
name = df.Name
Reviews = df.Reviews.replace("RATED\\n", "")
Reviews = Reviews.replace("\'", "")
Reviews = Reviews.strip('[]')
Reviews = Reviews.split("), (R")
Reviews_df = pd.DataFrame({'Text':Reviews})
Reviews_df['Rating'] = Reviews_df.Text.apply(lambda x: x.split(', ')[0])
Reviews_df['Review'] = Reviews_df.Text.apply(lambda x: x.split(', ')[1])
def clean_text(x):
text = x.replace("ated", "")
text = text.replace("R", "")
text = re.sub(r"[-()\"#/@;:<>{}`+=~|.!?,']", "", text)
text = text.lower()
return text
Reviews_df['Rating'] = Reviews_df['Rating'].apply(clean_text)
Reviews_df.Rating = Reviews_df.Rating.astype(float)
Reviews_df.Rating = round(Reviews_df.Rating/10,1)
def clean_text2(text):
text = text.lower().strip()
text = re.sub(r"i'm", "i am", text)
text = re.sub(r"he's", "he is", text)
text = re.sub(r"she's", "she is", text)
text = re.sub(r"that's", "that is", text)
text = re.sub(r"what's", "what is", text)
text = re.sub(r"where's", "where is", text)
text = re.sub(r"how's", "how is", text)
text = re.sub(r"\'s", " is", text)
text = re.sub(r"\'ll", " will", text)
text = re.sub(r"\'ve", " have", text)
text = re.sub(r"\'re", " are", text)
text = re.sub(r"\'d", " would", text)
text = re.sub(r"won't", "will not", text)
text = re.sub(r"can't", "cannot", text)
text = re.sub(r"n't", " not", text)
#text = re.sub(r"Rated)
text = re.sub(r">br<", " ", text)
text = re.sub(r"([-?.!,/\"])", r" \1 ", text)
text = re.sub(r"[-()\"#/@;:<>{}`+=~|.!?,'*\\]", "", text)
text = re.sub(r"[ ]+", " ", text)
text = text.rstrip().strip()
return text
Reviews_df.Review = Reviews_df.Review.apply(clean_text2)
Reviews_df = Reviews_df[['Rating', 'Review']]
#print("Name of the restaurant is :", name)
#print("Number of rows in the Dataframe :", Reviews_df.shape[0])
#return len(Reviews_df)
return Reviews_df.shape[0]
In case, you notice closely, you would see that we have simulated the similar function however, just changed name of a function as well as its return line.
def index_length(name): #provide the name of the restaurant
x = [] # to store the number of reviews
y = [] #to store the corresponding index number
index_list = [i for i in data_new.loc[data_new.Name == name].index]
if len(index_list)> 1:
for i in range(0, len(index_list)):
x.append(rating_reviews_2(index_list[i]))
y.append(index_list[i])
df = pd.DataFrame({"Index Value":y,"Review Length":x})
else:
print("This restaurant has only 1 branch and the index for it is :", index_list)
return df
The given function would provide us a data frame that will show the index prices together with total reviews for every branch of a given restaurant.
The sample is given here:

index_length("Baba Ka Dhaba")Therefore, this is about how we have prepared and cleaned the review data to get used for more text analysis.
Some analysis, which could be done through the given cleaned data are topic analysis, wordcloud generation, sentiment analysis (ensure the reviews are larger in size for the work), etc.
Still not sure? Contact Foodspark, and we will discuss your requirements in detail.
January 21, 2025 B2B marketplaces use data collection to expand and maintain relevance in the food industry. Organizations can improve...
Read moreJanuary 2, 2025 Web scraping has now become an important strategy in the accelerating world of e-commerce, especially for businesses...
Read more